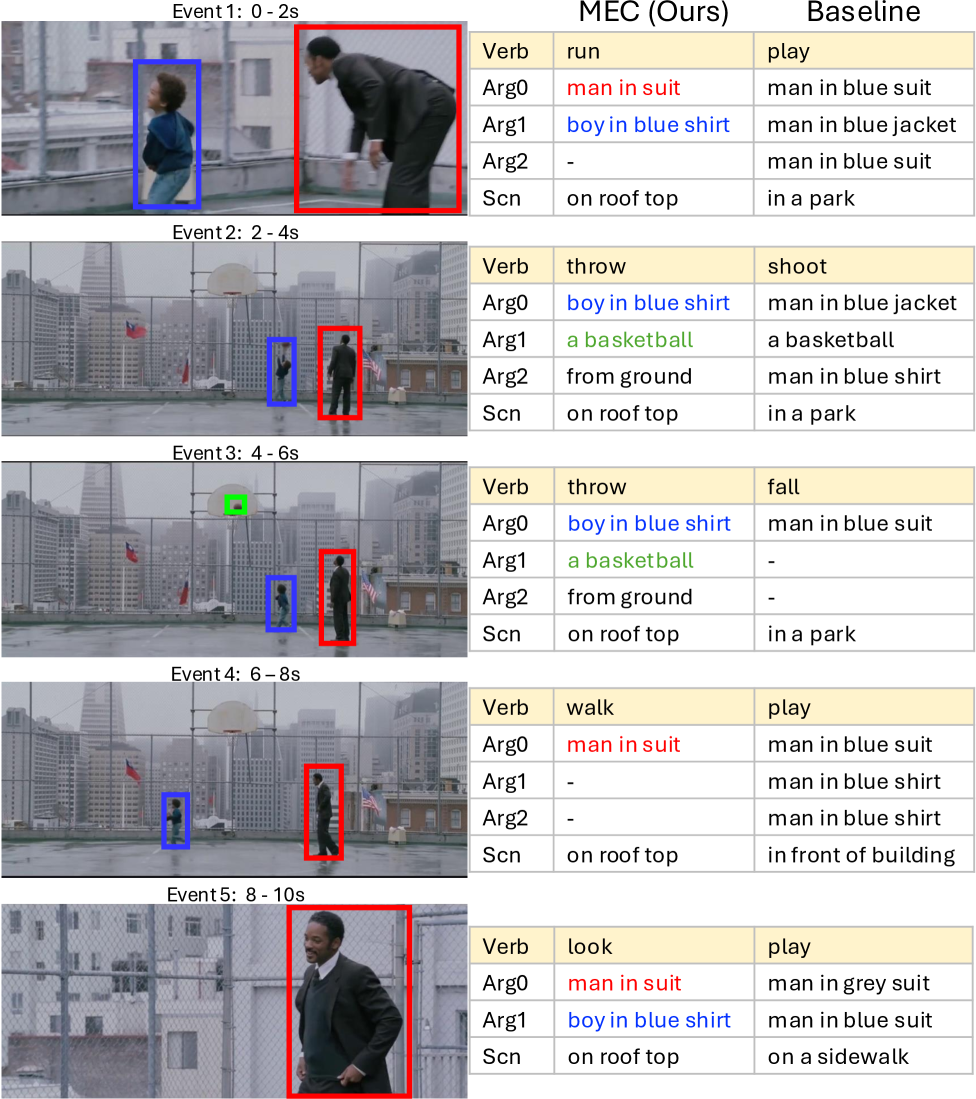
Video Situation Recognition (VidSitu) addresses the challenging problem of "who did what to whom, with what, how, and where" in a video. It tests thorough video understanding by requiring identification of salient actions and associated short descriptions for event roles across multiple events. Grounding with VidSitu requires spatio-temporal localization of key entities across shots and varied appearances. We posit that coherent video understanding requires consistent identification of entities that play different roles. We propose Multimodal Entity Coreference (MEC) to unite entity descriptions in text with grounding across the video. Towards this, we introduce CineMEC, a multi-stage approach that unites event role mention groups with visual clusters of entities, without explicit grounding supervision during training. Our approach is designed to exploit the synergy between visual grounding and captioning, where improving one influences the other and vice versa. For evaluation, we extend the VidSitu dataset with grounding annotations. While previous work focuses primarily on descriptions, CineMEC improves consistency across both: captioning (+2.5% CIDEr, +7% LEA) and visual grounding (+18% HOTA).
@inproceedings{darur2026cinemec,title={One Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation Recognition},author={Darur, Balaji and Garg, Amanmeet and Tapaswi, Makarand},booktitle={Findings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},year={2026},}
2025
C1
Visual-Aware Speech Recognition for Noisy Scenarios
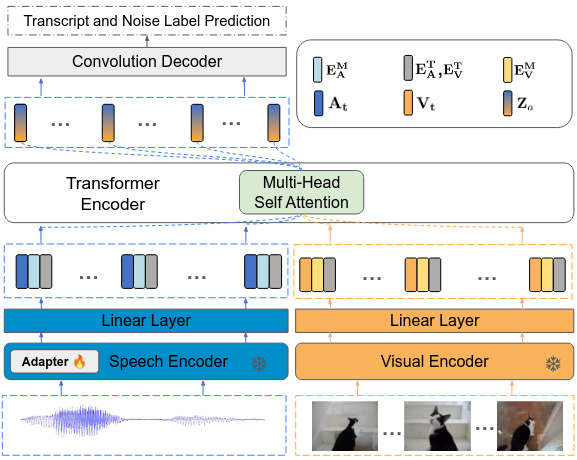
Humans have the ability to utilize visual cues, such as lip movements and visual scenes, to enhance auditory perception, particularly in noisy environments. However, current Automatic Speech Recognition (ASR) or Audio-Visual Speech Recognition (AVSR) models often struggle in noisy scenarios. To solve this task, we propose a model that improves transcription by correlating noise sources to visual cues. Unlike works that rely on lip motion and require the speaker’s visibility, we exploit broader visual information from the environment. This allows our model to naturally filter speech from noise and improve transcription, much like humans do in noisy scenarios. Our method re-purposes pretrained speech and visual encoders, linking them with multi-headed attention. This approach enables the transcription of speech and the prediction of noise labels in video inputs. We introduce a scalable pipeline to develop audio-visual datasets, where visual cues correlate to noise in the audio. We show significant improvements over existing audio-only models in noisy scenarios. Results also highlight that visual cues play a vital role in improved transcription accuracy.
@inproceedings{darur2025visual,title={Visual-Aware Speech Recognition for Noisy Scenarios},author={Darur, Balaji and Singla, Karan},booktitle={Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)},year={2025},note={Oral presentation, Short paper Main Track},}
W2
Freeze and Reveal: Exposing Modality Bias in Vision-Language Models
Vivek Hruday Kavuri, Vysishtya Karanam, Venkata Jahnavi Venkamsetty, and 3 more authors
In Interdisciplinary Workshop on Observations of Misunderstood, Misguided and Malicious Use of Language Models, co-located at RANLP 2025, 2025
Vision Language Models achieve impressive multi-modal performance but often inherit gender biases from their training data. This bias might be coming from both the vision and text modalities. In this work, we dissect the contributions of vision and text backbones to these biases by applying targeted debiasing using Counterfactual Data Augmentation and Task Vector methods. Inspired by data-efficient approaches in hate-speech classification, we introduce a novel metric, Degree of Stereotypicality and a corresponding debiasing method, Data Augmentation Using Degree of Stereotypicality - DAUDoS, to reduce bias with minimal computational cost. We curate a gender annotated dataset and evaluate all methods on VisoGender benchmark to quantify improvements and identify dominant source of bias. Our results show that CDA reduces the gender gap by 6% and DAUDoS by 3% but using only one-third of the data. Both methods also improve the model’s ability to correctly identify gender in images by 3%, with DAUDoS achieving this improvement using only almost one-third of training data. From our experiments, we observed that CLIP’s vision encoder is more biased whereas PaliGemma2’s text encoder is more biased. By identifying whether bias stems more from vision or text encoders, our work enables more targeted and effective bias mitigation strategies in future multi-modal systems.
@inproceedings{kavuri2025freezereveal,title={Freeze and Reveal: Exposing Modality Bias in Vision-Language Models},author={Kavuri, Vivek Hruday and Karanam, Vysishtya and Venkamsetty, Venkata Jahnavi and Madumadukala, Kriti and Darur, Lakshmipathi Balaji and Kumaraguru, Ponnurangam},booktitle={Interdisciplinary Workshop on Observations of Misunderstood, Misguided and Malicious Use of Language Models, co-located at RANLP 2025},year={2025},}
2024
W1
Improving Bias Metrics in Vision-Language Models by Addressing Inherent Model Disabilities
Lakshmipathi Balaji Darur, S.K. Gouravarapu, S. Goel, and 1 more author
In Workshop on Algorithmic Fairness through the Lens of Metrics and Evaluation, NeurIPS 2024, 2024
@inproceedings{darur2024improvingbias,title={Improving Bias Metrics in Vision-Language Models by Addressing Inherent Model Disabilities},author={Darur, Lakshmipathi Balaji and Gouravarapu, S.K. and Goel, S. and Kumaraguru, Ponnurangam},booktitle={Workshop on Algorithmic Fairness through the Lens of Metrics and Evaluation, NeurIPS 2024},year={2024},}